Começando com SQL Server na prática (Estrutura, inserção e consulta)
Aprenda a criar bancos de dados e manipular registros utilizando o Sql Server de forma simples e direta.
Sumário
- Introdução
- Conectando ao banco principal
- Criando o banco de dados
- Criando as tabelas
- Registrando informação no banco de dados
- Lendo registros do banco de dados
- Concluindo os registros
Introdução
Neste artigo iremos criar e manipular dados de tabelas de uma instância local do Microsoft SQL SERVER utilizando boas práticas no desenvolvimento de nossas queries. Nosso SGBD(Sistema gerenciador de banco de dados) será o Microsoft SQL Server 17 e está rodando em um container docker através do WSL. Usaremos o editor Azure Data Studio para desenvolver e executar as queries. Usarei o JetBrains DataGrip para exibição do diagrama de banco de dados para melhor exemplificar nossos passos.
O objetivo deste artigo é introduzir o leitor a um cenário prático de comandos SQL. O foco do desenvolvimento das instruções é desenvolver experiência com a execução dos comandos e analisando os resultados.
Este artigo está dividido em duas partes. Nesta primeira parte aprenderemos a criar o banco, inserir e consultar registros. Na segunda parte iremos aprender a editar e deletar informações e estrutura do nosso banco.
Caso não tenha os recursos acima descritos instalados você pode fazê-los através destes artigos:
Docker - Instalação, Configuração e primeiros passos
Azure Data Studio - Download e instalação
Conectando ao banco principal
Tendo nosso SGBD e editor instalados precisamos nos conectar ao banco de dados, para isto iremos abrir o Azure Data Studio e clicar no botão de nova conexão que fica no canto superior esquerdo da janela logo abaixo do menu principal.
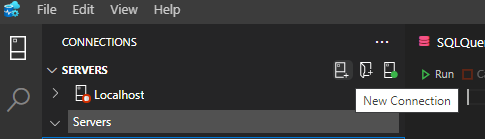
Precisamos então nos conectar ao banco com o nome Master que é um banco criado por padrão durante a instalação. Para isto precisamos preencher os campos do formulário que aparece logo em seguida.
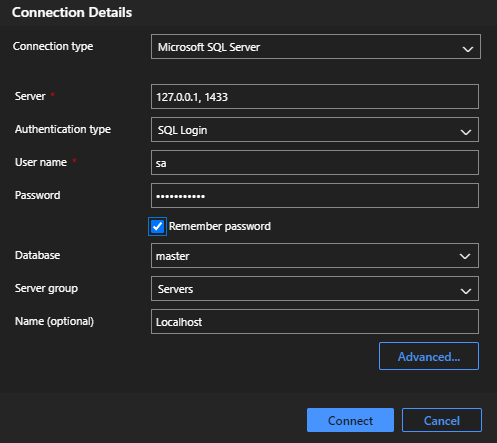
Os campos são:
Connection type
tipo de conexão (manter o padrão Microsoft Sql Server);
Server
O Servidor ao qual deseja se conectar. Você pode inserir localhost ou 127.0.0.1 para servidores locais ou o ip ou domínio do servidor.
Authentication type
O tipo de autenticação que utilizará para se conectar ao banco. Sql Login é a opção onde voc~e deve inserir um nome de usuário e senha para se conectar. Caso seu banco tenha autenticação por usuário do Windows ativa, você pode se conectar utilizando a opçao Windows Authentication que não solicita credenciais e se conectará caso seu usuário tenha registro de acesso.
Database
Aqui selecionaremos a instância que iremos nos conectar. Como ainda iremos criar nosso banco, selecionaremos a master que é criada durante o processo de instalação do Microsoft Sql Server. Acessaremos esta instância para desenvolver o script de criaçao do banco e posteriormente nos conectarmos à instância do banco criado.
Server group
O Grupo do servidor pode ser criado aqui caso não tenha um. Ao criar, será adicionado no menu vertical uma aba com o nome do grupo e os servidores que você incluir nele seram exibidos dentro. Esta opção é para fins de organização da visualização. Muito útil em cenários onde se trabalha com diversos servidores.
Name
Por fim temos o nome. Aqui daremos um nome para o conjunto de configurações que acabamos de fazer. Este nome não tem influência sobre a conexão e será usado como identificador dessas configurações dentro do Azure Data Studio.
Criando o banco de dados
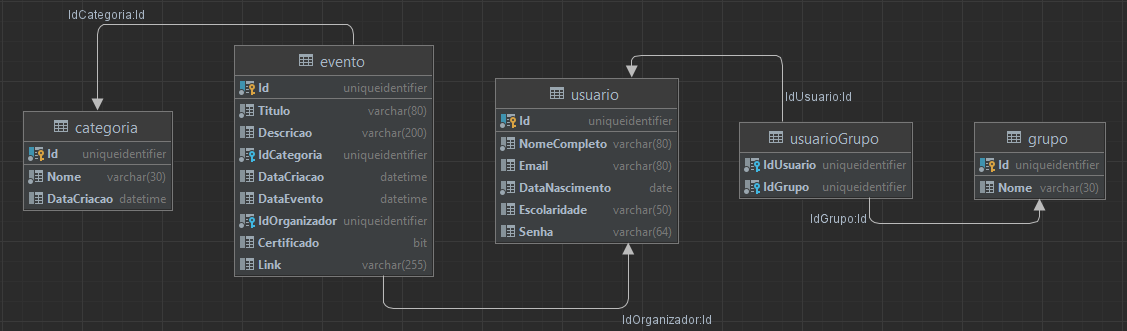
Criaremos um banco simples com a estrutura exemplificada acima. Temos uma tabela de eventos que faz referência para a categoria do evento e ao organizador. O organizador por sua vez pertence à um grupo que define seu acesso.
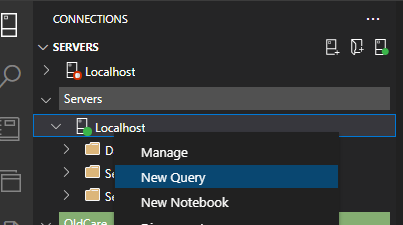
Para começarmos a escrever nossos scripts vamos clicar com o botão direito sobre o nosso servidor que acabamos de configurar e selecionar New Query para criar nossa primeira query.
Então digitaremos o seguinte comando:
IF NOT EXISTS (SELECT * FROM sys.databases WHERE name = N'eventos')
BEGIN
CREATE DATABASE [eventos]
END;
Na primeira linha estamos fazendo antes de tudo uma verificação. Ela inicia com o IF NOT EXISTS para verificar se o banco já existe. A condição que estamos passando dentro dos parenteses é um SELECT que veremos mais a frente. Este select tenta encontrar um banco de dados com o nome citado. Caso não exista ele executará o comando CREATE DATABASE [] que cria um banco de dados com o nome passado.
Nota: Note que ao darmos o nome do banco, usamos [] Colchetes.
Para executar o comando acima podemos apertar F5 ou clicar no botão RUN acima do nosso script.
E abaixo teremos a confirmação da execução:
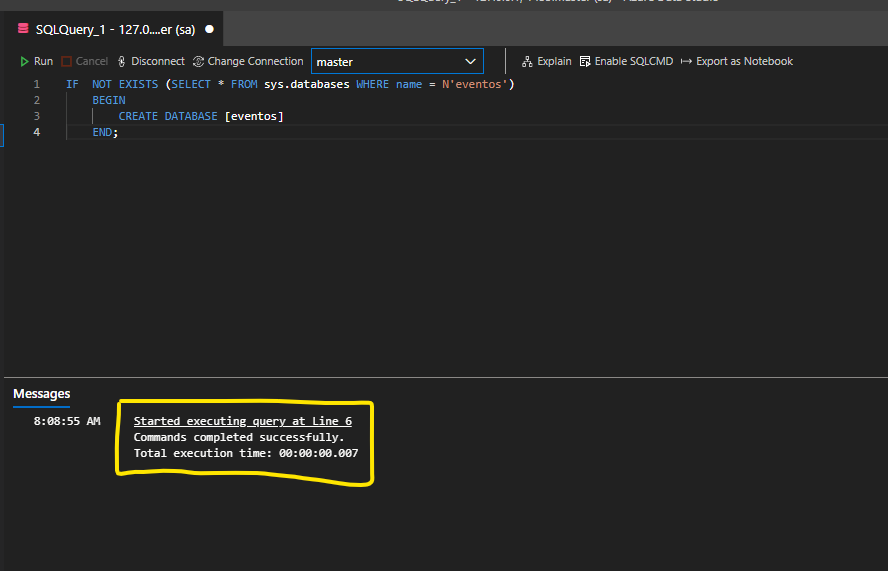
Criando as tabelas
Agora neste mesmo script iremos criar as nossas tabelas. O trecho ficará assim:
USE [eventos]
GO
IF NOT EXISTS (SELECT * FROM sysobjects WHERE name='grupo' and xtype='U')
BEGIN
CREATE TABLE [grupo] (
[Id] UNIQUEIDENTIFIER NOT NULL,
[Nome] VARCHAR(30),
CONSTRAINT [pk_grupo] PRIMARY KEY ([Id])
)
END
IF NOT EXISTS (SELECT * FROM sysobjects WHERE name='usuario' and xtype='U')
BEGIN
CREATE TABLE [usuario] (
[Id] UNIQUEIDENTIFIER NOT NULL,
[NomeCompleto] VARCHAR(80) NOT NULL,
[Email] VARCHAR(80),
[DataNascimento] DATE NOT NULL,
[Escolaridade] VARCHAR(50),
[Senha] VARCHAR(64),
CONSTRAINT [pk_usuario] PRIMARY KEY ([Id])
)
END
IF NOT EXISTS (SELECT * FROM sysobjects WHERE name='usuarioGrupo' and xtype='U')
BEGIN
CREATE TABLE [usuarioGrupo] (
[IdUsuario] UNIQUEIDENTIFIER NOT NULL,
[IdGrupo] UNIQUEIDENTIFIER NOT NULL
)
END
IF NOT EXISTS (SELECT * FROM sysobjects WHERE name='categoria' and xtype='U')
BEGIN
CREATE TABLE [categoria] (
[Id] UNIQUEIDENTIFIER NOT NULL,
[Nome] VARCHAR(30) NOT NULL,
[DataCriacao] DATETIME DEFAULT GETDATE(),
CONSTRAINT [pk_categoria] PRIMARY KEY ([Id])
)
END
IF NOT EXISTS (SELECT * FROM sysobjects WHERE name='evento' and xtype='U')
BEGIN
CREATE TABLE [evento] (
[Id] UNIQUEIDENTIFIER NOT NULL,
[Titulo] VARCHAR(80) NOT NULL,
[Descricao] VARCHAR(200),
[IdCategoria] UNIQUEIDENTIFIER NOT NULL,
[DataCriacao] DATETIME DEFAULT GETDATE(),
[DataEvento] DATETIME,
[IdOrganizador] UNIQUEIDENTIFIER NOT NULL,
[Certificado] BIT DEFAULT 0,
[Link] VARCHAR(255),
CONSTRAINT [pk_evento] PRIMARY KEY ([Id])
)
END
Note algumas características que procuramos sempre seguir:
1 - Verificar se o que iremos criar já existe;
2 - Queries sempre em letras maiúsculas;
3 - Nomes de bancos, tabelas e atributos declaramos sempre entre chaves [].
Observe que usamos o USE [nomedobanco]. Com este comando podemos trocar de um banco de dados para outro sem precisar criar uma outra conexão. Mas claro, só funciona se o usuário que está executando a query tiver permissão equivalente nos dois bancos. Do contrário será necessário seguir os passos indicados no início do artigo e criar uma nova conexão com o banco criado passando as credenciais de um usuário válido.
Usamos também o comando CREATE TABLE [nomedatabela]() e dentro dos parenteses passamos os atributos um por linha.
Nossos parametros nestes scripts SQL são definidos assim: [nome] TIPO(TAMANHO) VALOR/DEFINIÇÂO. O Nome do atributo entre os colchetes, o tipo logo depois com o tamanho ao lado dentro de parenteses e por último definimos NOT NULL se quisermos que seja exigido um valor do campo. Deixamos em branco se quisermos permitir que o campo seja vazio/nullo.
E como resultado o banco gerado fica assim:
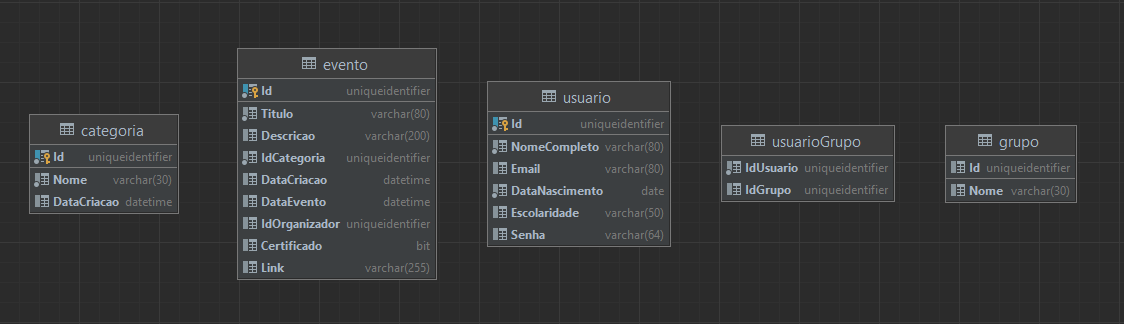
Foreign Keys
As foreign keys ou chaves estrangeiras são conceitos que funcionam para interligar tabelas através de atributos representando um relacionamento. Podemos pegar como exemplo a tabela usuarioGrupo. Este tipo de tabela (tabela de quebra de relacionamento) faz referência a um Id de usuário e um grupo específico. Com isto podemos saber quais usuários pertencem a certo grupo e vice versa.
As foreign keys também podem ser usadas para especificar que um usuário só pode ser atribuído à um grupo existente. E um evento precisa de uma categoria existente e um usuário existente para ser criado.
Faremos isto através do seguinte trecho de código:
USE [eventos]
GO
IF NOT EXISTS (SELECT * FROM sys.objects o WHERE o.object_id = object_id(N'[dbo].[fk_usuarioGrupo_usuario]'))
BEGIN
ALTER TABLE [dbo].[usuarioGrupo]
ADD CONSTRAINT [fk_usuarioGrupo_usuario] FOREIGN KEY ([IdUsuario])
REFERENCES [dbo].[usuario] ([Id]);
END
IF NOT EXISTS (SELECT * FROM sys.objects o WHERE o.object_id = object_id(N'[dbo].[fk_usuarioGrupo_grupo]'))
BEGIN
ALTER TABLE [dbo].[usuarioGrupo]
ADD CONSTRAINT [fk_usuarioGrupo_grupo] FOREIGN KEY([IdGrupo])
REFERENCES [dbo].[grupo] ([Id]);
END
IF NOT EXISTS (SELECT * FROM sys.objects o WHERE o.object_id = object_id(N'[dbo].[fk_evento_categoria]'))
BEGIN
ALTER TABLE [dbo].[evento]
ADD CONSTRAINT [fk_evento_categoria] FOREIGN KEY([IdCategoria])
REFERENCES [dbo].[categoria] ([Id]);
END
IF NOT EXISTS (SELECT * FROM sys.objects o WHERE o.object_id = object_id(N'[dbo].[fk_evento_usuario]'))
BEGIN
ALTER TABLE [dbo].[evento]
ADD CONSTRAINT [fk_evento_usuario] FOREIGN KEY([IdOrganizador])
REFERENCES [dbo].[usuario] ([Id]);
END
E assim teremos atribuido os relacionamentos entre as tabelas que precisamos. Como demonstra a imagem abaixo:
Registrando informação no banco de dados
Agora que construimos o nosso banco podemos começar a popular ele. Então vamos criar um registro em cada tabela para que possamos prosseguir.
BEGIN TRANSACTION
INSERT INTO [categoria] VALUES (
NEWID(),
'Palestra',
GETDATE()
)
INSERT INTO [grupo] VALUES (
NEWID(),
'Palestrante'
)
INSERT INTO [usuario] VALUES (
NEWID(),
'Brewerton Santos',
'mail@mail.com',
'2022-01-20 20:00:47.093',
'superior - cursando',
'1a2b3C%'
)
ROLLBACK
NOTA I: O Comando INSERT INTO [nomedatabela] VALUES() funciona também sem o uso de TRANSACTION mas fechamos a transação com ROLLBACK para que possamos executar o comando sem salvar as modificações. Assim sabemos se o comando foi executado sem nenhum problema e quando tivermos certeza do resultado podemos substituir o ROLLBACK por COMMIT e assim as modificações serão salvas no banco.
Para continuarmos com o registro das nossas informações vamos precisar saber o identificador que foi gerado nos registros anteriores. Então antes de começarmos precisamos passar pelo SELECT primeiro.
Lendo registros do banco de dados
O comando SELECT permite que possamos consultar informações registradas no nosso banco de dados. É desta forma que iremos consultar o Id da nossa categoria de palestras, grupo de palestrantes e posteriormente o nosso usuário.
O trecho de código para consulta ficará assim:
SELECT
*
FROM [eventos].[dbo].[categoria]

NOTA II: O asterisco indica que queremos consultar todos os dados da nossa tabela. Neste contexto não é um problema já que sabemos que temos apenas um registro. Mas como por exemplo, em um cenário de muitos registros é necessário especificar informação para reduzir o número de linhas retornadas.
Vamos consultar apenas a primeira linha da nossa tabela de grupos para termos um exemplo de como fazer uma busca específica:
SELECT TOP (1)
[Id]
FROM [eventos].[dbo].[grupo]
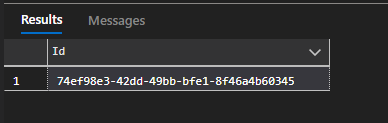
Veja que limitamos apenas ao primeiro registro que for encontrado através do parametro TOP (1) e também específicamos que queremos que seja exibido apenas o Id do grupo já que temos apenas um registro, sabemos que o retorno será o Id do grupo de palestrantes.
Para consultar nosso usuário vamos especificar que queremos trazer um usuário com sobrenome Santos. Como sabemos que só há um registro e ele tem este sobrenome. Ele trará nosso usuário cadastrado anteriormente. Veja como fica o trecho de código no exemplo abaixo:
SELECT
[Id],
[NomeCompleto],
[Email],
[DataNascimento],
[Escolaridade],
[Senha]
FROM [eventos].[dbo].[usuario]
WHERE [NomeCompleto] LIKE '%Brewerton%'
Nota: O operador LIKE seguido da palavra-chave entre aspa simples e porcentagem pesquisa na tabela a palavra-chave.

Concluindo os registros
Agora que sabemos o Id do grupo, categoria e usuario criados podemos continuar a população das tabelas.
Atribuindo um grupo ao usuário:
BEGIN TRANSACTION
INSERT INTO [usuarioGrupo] VALUES (
'e83848d3-cffd-4445-bf7a-2996583e834a',
'74ef98e3-42dd-49bb-bfe1-8f46a4b60345'
)
ROLLBACK
O primeiro identificador inserido é o Id do nosso usuário. O segundo identificador é do grupo de palestrantes.
E vamos consultar para ter certeza de que todos os dados foram registrados corretamente. Faremos uma consulta um pouco mais avançada. Utilizando o INNER JOIN iremos fazer a junção de 2 tabelas e exibir juntos os resultados em uma única linha.
SELECT
[usuario].[Id] AS IdUsuario,
[usuario].[NomeCompleto],
[usuario].[Email],
[grupo].[Id] AS IdGrupo,
[grupo].[Nome] AS Grupo
FROM [usuario]
INNER JOIN [usuarioGrupo] ON [usuarioGrupo].[IdUsuario] = [IdUsuario]
INNER JOIN [grupo] ON [grupo].[Id] = [usuarioGrupo].[IdGrupo]
WHERE [NomeCompleto] LIKE '%Santos%'
NOTA III: Indicamos os campos que queremos que sejam retornados e usamos o operador AS para renomear a coluna que irá exibir os dados. Adicionamos mais duas tabelas aos resultados utilizando o INNER JOIN e utilizando o relacionamento entre as tabelas. Também especificamos que queriamos trazer apenas os registros que tenham Santos no nome.
Considerações finais
Passamos pela conexão e criação do banco. Estruturação, inserção e consulta dos dados. Na proxíma parte iremos aprender a fazer consultas avançadas, desenvolver stored procedures, editar informações dos registros e tabelas e excluir registros, tabelas e até mesmo bancos de dados inteiros.
NOTA IV: Os contextos exibidos neste artigo podem ser desenvolvidos facilmente. Caso o leitor sinta vontade e/ou necessidade de entender mais detalhadamente os comandos, instruções e ferramentas utilizadas é recomendado acompanhar o curso Fundamentos do SQL Server.
Continue lendo:
Começando com SQL Server na prática - Parte 2 (Consulta avançada, edição e remoção de dados)